Before you begin reading this article, it is important to clarify which topics will not be covered:
- This article will not answer the question of which method is better, because the answer is not binary.
- This article will not recommend which technology you should use, but it will discuss a number of tools and solutions that could be helpful for you.
What will be covered in this article are the following:
- This article will focus on the most important topics that require your attention before migrating your Data Warehouse to a Data Lake.
- This article will give you a pretty good idea of which direction you should take regarding a migration from Data Warehouses to a Data Lakes.
Since the topic of non-relational data and Big Data is a “grey” area that uses many buzz words, with numerous vendors scrambling to garner market share, there really is no set best practice. In other words, each organization has its own unique needs and requires an individualized approach regarding technology adaptation.
Some of you may be thinking that you don’t need to read the rest of this article, because from the title it seems obvious that the topic is “Moving from a Data Warehouse to a Data Lake.” If you just bear with me for a few moments, I will begin by discussing the differences between Data Warehouses and Data Lakes.
Later on in the article, I will try to elucidate the subject for you through technical examples and probable scenarios.
Let’s start with a few basic explanations:
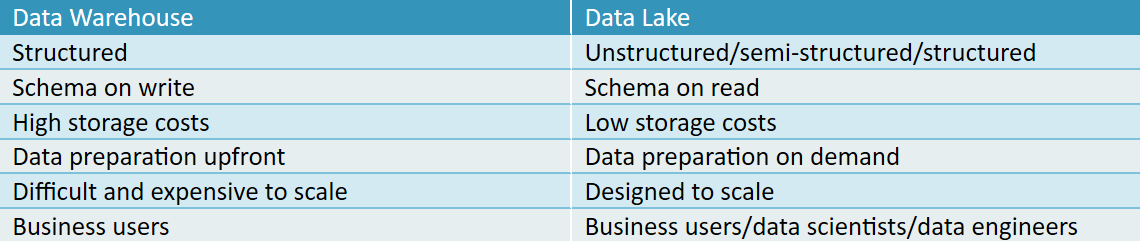
Data Warehouses
Data Warehousing is a method used to store structured data in a relational schema. The data sources are varied and usually come from Online Transaction Processing (OLTP), Enterprise Resources Planning (ERP) and Customer Relationship Management (CRM) systems, in a process called Extract, Transform, and Load (ETL).

The main goal of Data Warehousing is to transform data into a structured format that supports business logic and enables BI tools to create analysis and reports representing “one version of the truth”.
Two of the most common schema types used in Data Warehouses are Snowflake Schema and Star Schema. These schemas are crucial for specific issues, such as:
- Historical data quarrying and changing data over time
- Data quality and integrity
- High quarrying performance and ease of reporting
Data Lakes
Data Lake is a relatively new term that became more popular as the reality of petabyte and exabyte ranges of data collected in organizations, including real-time streaming data, online events and logs, needed to be stored, handled and analyzed. Data Lakes can hold structured and unstructured data by providing the flexibility to analyze data from different angles and enhance analytic capabilities by answering multiple business questions from a variety of stored data sources. Moreover, Data Lakes are capable of handling massive volumes of stored data.
Data Lake Weaknesses
- Data governance
- Solution might be expensive computing-wise
- Complexity creating secured data read per end user
Data Warehouse Weaknesses
- Preparation and maintenance costs and time
- Unstructured data types
2 Concepts, 1 Solution
As mentioned before, we are dealing with two types of concepts, but this doesn’t mean that they don’t “walk hand in hand together”. Usually, when an organization uses data from budgets for data development, it focuses on a specific solution that is promoted as the correct method of choice by a vendor or an untrustworthy consultant who is offering misleading advice. You should use the budget for warehousing since it’s hard to manage metadata or data accuracy in Data Lake. On the other hand, you might get the opposite advice from a consultant, since it could be very expensive to store data if there is a chance that the number of company transactions will increase, or if you would like to use data science models with varied data sources and types.
The truth is, there is no binary answer to the question of which method is preferable. Each solution must consist of both methods, since as you read in previous chapters, each method is designed for different purposes and has its own pros and cons.
If you are dealing with accounting data, sales, inventory and customers, I would strongly recommend that you continue working with your Data Warehouse in order to achieve the most accurate numbers.
On the other hand, if you are dealing with data coming from social media, web logs, streaming data or call center data, I would strongly recommend that you use Data Lakes.
Moving From a Data Warehouse To a Data Lake
You might already have guessed that this chapter will explain how to move from Data Warehouse to Data Lake technology using data engineering best practices, while adhering to the concepts of Data Warehouse design. Disclaimer: In some cases, I would strongly recommend continuing to use the conservative Data Warehouse method, as mentioned before.
- Architecture
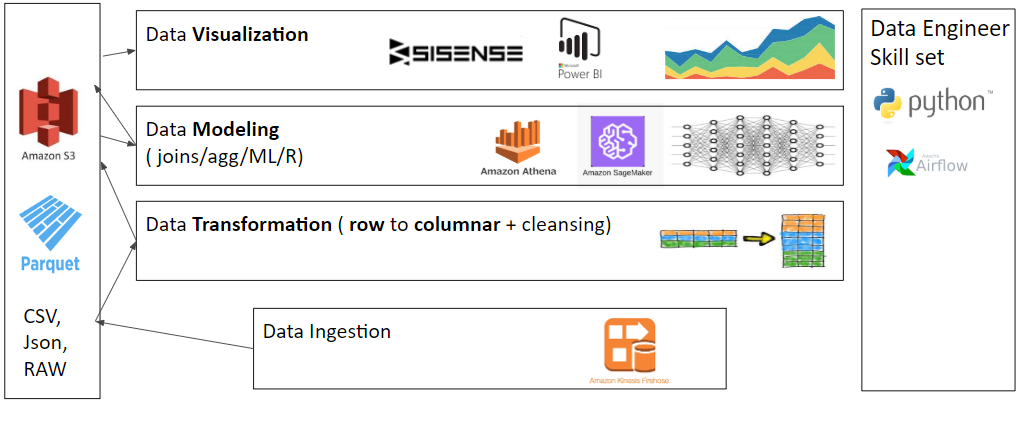

Let’s dive straight into the architecture for Data Lake implementation. As illustrated above, you can see that the 3-stage Data Lake model has parallels to the Data Warehouse technique (ie. mirroring, staging and modeling layers), which is recommended regardless of whether you use AWS or GOOGLE.
This architecture is convenient for keeping everything in order. If a problem arises from one of the layers, it is easier to understand where and how to fix the problem.
There a few different options for how to implement this architecture:
- If you want to retain Data Warehouse capabilities, with fully-managed, data governance, and still enjoy the benefits of cloud computing and storage on demand, my suggestion would be to use Amazon Redshift or Google Big Query. You do, however, need to take into consideration that this is a relatively expensive solution, which also requires a team member with specific expertise and knowledge.
- If you want to implement a lean solution, I would recommend continuing to use your current Data Warehouse and consider the following option:
- If you are new to using the cloud, it would be beneficial to start by adding new data to your storage by putting it through the layers of the architecture and learning how to work with Airflow. In the meanwhile, you can bring your schema of the Data Warehouse tables to the modeling layer.
- If you already know how to work in a cloud environment and want to get rid of your traditional ETL process, I would recommend starting by migrating your queries from the ETL process to a layers architecture, in which the Data Ingestion layer corresponds with Mirror tables, Data Transformation corresponds with Staging tables, and Data Modeling corresponds with Data Warehouse tables.
You should take into consideration that this process is perfect for a “full load” Data Warehouse. If you want to stay in the “upsert” configuration, it starts to get more complicated and requires some expertise. There’s also the Slowly Changing Dimension Technique, which is more difficult to manage in the Data Lakes, but it is possible.
- Steps for Data Lake creation
- Create the right business justification and treat it as a business project – not a technology project.
- Build an architecture that will support your data
- Pick a data governance tool
- Create your Data Lake in stages:
- First, populate your Data Lake with raw data from internal and external data sources, supporting the main business use case, while enhancing your data team skills.
- Next, introduce your data science team to your Data Lake environment, so that they can test and learn for which “area” of data your scope should be expanded.
- Then, inject your existing Data Warehouse into the Data Lake, while safeguarding the business logic, schema and correct metadata. It is recommended that you keep your Data Warehouse “alive” for a predetermined period of time, so that it can be examined for performance and accuracy.
- Lastly, access all your data in the Data Lake, which will now be your core platform. Data can be kept as a service to business users and developers, so long as data governance is strictly enforced.





