The first time I dealt with database internals code, was back in 2014, when I worked with MonetDB, an open-source column-oriented DBMS used for analytics (column store is mainly designed to support efficient OLAP kind of queries and workloads and not OLTP). MonetDB was implemented in the C-language and as in any database, has both advantages & flaws. Although the developers implemented a lot of sophisticated modules to handle different database functionality, the code for the database basic functions was quite simple & straightforward. It is also a total mess. The reason for that isn’t the fact it is written in that god forsaken C-language (I sure don't think like that). Apparently it is (almost) the same case with a much more modern (great!) database – ClickHouse, written (beautifully) in modern C++.
Before diving into details, let me explain what I mean by a database function. Every database (or any ETL/data engine for that manner) have a lot of non-aggregative functions (i.e.: functions that work on a dataset - one column or more, and return a result of the same size):
- String functions: concat, subString, toUpper, toLower etc.
- Date functions: toDate, dateDiff, toDayOfweek etc.
- Math functions: plus, minus, multiplication, power, exponent etc.
- Conversion function: toInt, toString, etc.
- And more.
For the simplest case, any one of these functions can appear in a SELECT clause of a very simple query like this:

or like that:

Of course the queries can get much more complex, and so are the different usages of these functions (e.g.: a function could be used on top of a condition or another function results).
Now, if you don’t think about the implementation of these functions deeply, you might think something like: ‘well, it might be a lot of work to implement so many functions, but basically each one should be quite a straightforward work’ (once we’re done with all that parsing...Yuck!). You couldn't be more wrong, as you might have overlooked the fact that each such function in a database, ETL or data processing engines, isn’t really a function, it is more like a multi-function (details below), and guess what - that’s where it gets really interesting.
This article will be divided to a few digestible parts:
- Introduction to the problem: what exactly are these multi-functions and what implementation and testing challenges they raise (part I). On this part I hope to get your attention and probably some kind of consent, that this is indeed a problem.
- Examination of some simple possible solutions, including taking a bird’s eye view of how the problem is actually solved in two different modern databases: MonetDB & ClickHouse (part II). Here, the real DB examples will serve in convincing you that I’m not bluffing and surely not imagining a problem that isn’t there (BTW - does anyone else hear that chilling whisper at nights?).
- An article introducing advanced modern C++ template meta-programming (TMP) techniques that will be used as building blocks for my solution on next part (part III).
- The climax of this article - my suggested solution to the problem raised, using advanced modern C++ TMP code built upon the building blocks presented in part 3 (part IV). Here I hope to convince you that TMP is an amazing and powerful C++ sub-language that fuels a very nice & powerful solution to the problem. Maybe after this, many of the readers will stop thinking of TMP as some kind of a curse or a pure-academic, bad taste programming practice *.
Well, what the heck is this multi-function I mentioned earlier? Let’s have a look at the concat function. In general, concat is a string function with the following signature: concat(string str1, string str2). This function basically returns a concatenated string of str1 & str2 with the result string's length being the sum of lengths. Example: concat(‘what a ‘, ‘nice day’) will return the string ‘what a nice day’.
For discussion purposes we’ll refer to the previous function as the ‘scalar function’ version of concat, as both arguments are constants. In a database/ETL query, each one of the arguments might actually be a vector (e.g.: a table column, a result of a previous sub-query, etc.) or a scalar/constant. Indeed, we can also have the following 3 different usages of concat:

It doesn’t really matter if the above makes sense in the “real” world (we can think of a better, more complex use-cases), the fact remains: we, as database designers, have 4 different cases to implement when we consider supporting the concat functionality – one scalar version (all parameters are constants) and 3 different vector versions (when at least one of the parameters is a vector).
Let's look at another multi-function: the subString function; This is a string function with the following signature: substring(string str, int firstIndex, int length), which returns a substring of the string str, starting at index firstIndex with max length of length (example: substring("Hello world!", 6, 5)= "world"). Here, we actually have 3 function parameters, so basically have 2^3 = 8 different versions of the function to implement!
Thus we see that every such function in a database is indeed a multi-function, because it has different versions with different parameters (T != vector<T>, for every parameter of type T). In general we conclude that a database function with n inputs has actually 2^n different versions! If you are not convinced, another way to look at it is to have a look at a full truth table for n bits, denoting '0' as a scalar parameter (i.e.: constant) and denoting '1' as a vector parameter (i.e.: table column).
Now, in most cases, you’ll see 4 separate function implementations for concat (all are quite similar, probably written with plain-old copy-paste manner with little changes) and 8 different versions of subString. This is what I refer to as the 'database functions implementation fan out problem'. In the simplest form, stripping all the details (input checks, exception handling, abstract classes/interfaces to handle different types etc.) the code for concat will look something like that:
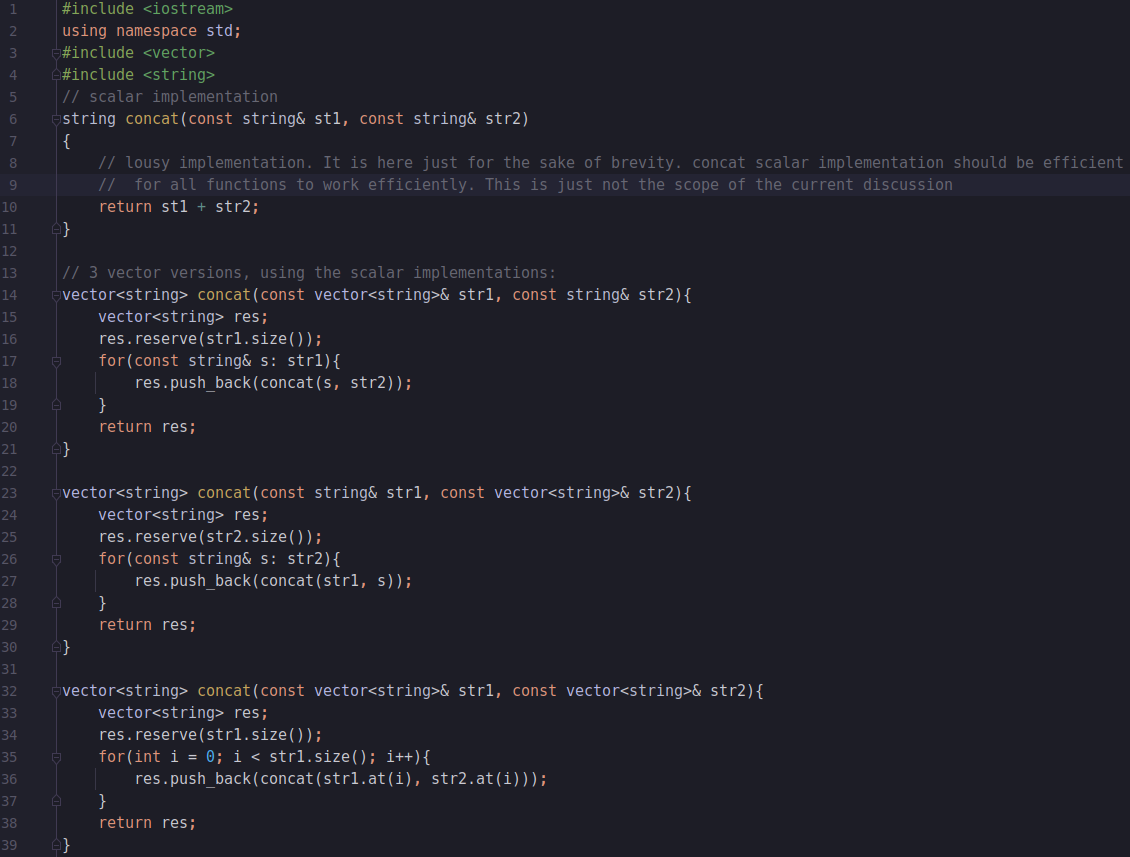
Well, as I said, copy-paste plus small changes. Not a problem, right? Think again… Here are just a few things to consider:
- Code duplication is just horrible. One small mistake would require us to touch all functions.
- How do we test this? We should probably write 2^n different tests for each function with n inputs. Why? Because there are 2^n different implementations! Similar as they may be, copy-paste with changes isn’t bullet-proof. You need to test them all to make sure they work. No free meals here.
- If that doesn’t sound too bad, consider this scenario: a database / ETL engine implementer will be required to implement not only the concat or subString multi-functions, but more likely dozens, if not hundreds, of such multi-functions. Each one of these with 2/4/8/16/… different versions (depends on the number of parameters).
- No one likes to write boilerplate code (which is one of the major issues that templates and TMP try to solve, BTW). Once you implement the scalar version of subString (after researching deeply and experimenting many library versions to come up with the most effective solution), you just need some boilerplate code to allow all 8 database versions of it (have another look at concat above). But it is boring to write that code and test it, and it seems like a lot of work no one will like to do.
The last point actually was born in a true story, so I'll break this tech-talk for a short story-telling; I was working on an ETL engine and after a very hard work on the query language, parser, compiler, database catalog, execution mechanisms & many more modules, I actually got to the time I needed the basic functions... and there were 47 of them..at the 1st MVP only (Actually, I got lucky. When I got this demand, I've decided to get it over with, but we were sitting on 2nd floor, so hitting the ground wasn’t that hard…). I finally got another engineer on the team, and without thinking about it deeply, I asked him to help me implement these 47 functions, one by one, with testing, to make sure they work and work effectively on a large scale. Hard work, but not too bad right? Wrong! 2 days into the task he bumped into the previously mentioned problem: it ain’t 47 functions to implement and test, it’s more like 150-200 (some with 2 versions, some with 4, 8 or even 16).
If I only knew back then what I now know about TMP...
I hope that by now, I’ve convinced you that there is a real problem here, or at least a challenge. On the next part I’ll show you (from a bird’s eye view) how MonetDB and ClickHouse tried to tackle this issue (ClickHouse made a better effort. Still horrible solution to me). I'll also show a simpler, less effective (performance-wise) solution that solves part of the problem. I'm sure you can also come up with a few solutions, but your should remember these basic ground facts:
- such multi-function implementations in a database should be extremely effective and perform well (especially on a column store database running OLAP analytical queries on billions of rows).
- If you come to your boss with a solution that avoids code duplication, is neat and easy to maintain but runs 200% the time the plain old duplicated code runs - he'll throw you through the window...
So, if I you're interested, willing to put the effort to learn new TMP techniques and want to see how other products has solved this problem, please join me on part 2 of this article that will be published soon.
See you soon!
_________________________________________________________________________
* This is not an empty prognosis. Most people think and express this way about TMP. On my previous article The beauty and the beast, I got a comment stating that TMP is only good for academic experimentation and for fun. In addition the commenter said that many companies don't allow hardcore TMP because they value their workers time and afraid from 'dead code' no one could touch ever again (like a white walker I guess, dead and alive :)). A more common comment is that TMP are hard to debug, code, maintain and test. Although this is the common perception, needless to say, I tend to disagree (to say the least). I believe, that like C++ to non-C++ programmers, TMP has a high entry bar and that's why almost everyone, including C++ professionals, have ignored it for the last 20 years (I talk about these kind of things in the article stated above). But the beast is now awaken in modern C++, or as other commenter to my article quoted: "Only brave people write about templates" (Meyers on Alexandrescu).





